
今回はTransformerについて色々調べて自分なりにまとめてみました。
写真は16:9にするために横にしました…。
Bert等の最新の高性能モデルにもつながる大事なモデルであるらしい…。「よく聞くなぁ」とか「学んでみたいけど…」と思っているけど、難しそうという壁がある人のため、自分のためにまとめてみました。ぜひ見ていってください。
※注意:間違いがあるかもしれません。生暖かく見守っていただけると幸いです。
※分類するテキストは英文です。
この記事はネット上の様々な情報と
「Attention Is All You Need」
この原論文をもとに、自分なりに解釈し作成しています。間違いもある可能性もありますが、生暖かく見ていただければ幸いです。

Transformerまでの流れと特徴(何となくならこの章だけでもOK)
流れ
RNN系NNは時刻$t$の隠れ層の出力が時刻$t+1$の隠れ層に影響するような構造をしているため、前の状態を受け取らなければいけない
→計算の並列化は本質的に難しく、計算が遅いのが最もクリティカルな課題。
→計算効率が低く、たくさんのデータで学習しにくいのが問題よね
+
先頭の影響が次第に薄れるため、入力が長いと離れた単語間の関係が捉えきれない
↓
CNNって使えそうじゃない?いや無理か、、、
CNN等はエンコーダとしては優れているが、時間情報を埋め込むことは不可能である。単語の並びが無視され、翻訳などの自然言語処理系では使用に対して課題が多い。
↓
周囲の単語に対する重み付けをする機構が必要
↓
Attention機構の登場とともに、これ使えるな
↓
新たなニューラルネットワーク構造として、2017年にトランスフォーマー(Transformer)という、Attention機構をベースとした構造
特徴
Attention機構をベースとした構造である。
そもそもAttention機構とは…
Attentionとは簡単に言うと、文中のある単語の意味を理解する時に、文中の単語のどれに注目すれば良いかを表すスコアのことで、前回の記事で説明してみている。

↓
実際に用いられているSelf-Attentionは入力ベクトルのみから出力を並列計算で導出可能で計算依存性がなく、 計算時間はO(1) という、めちゃくちゃ早い速度である。Self-AttentionはRNN、CNNセルよりも計算する要素が少なく高速である。
原論文より

Self-Attentionのおかげで遠い位置にある単語同士の関係もうまく捉えることができる。
まとめ
- Attention機構がメイン(RNNやLSTM、CNN層は一切使っていない)
- Attention機構のおかげで並列計算が可能+計算量が少ない
加えて、
- 汎用性が高い→BERT,GPT等につながる
- 勉強しておいて損がない存在である
Transformerの構造・原理
全体の構成・概要

Transformerは基本的な大枠はエンコーダ-デコーダモデル
self-attention層とPosition-wise全結合層(Position wise FFN)を使用していることが特徴。
図でいう左側がエンコーダ、右側がデコーダ
エンコーダ:単語をインプットとして、文章の埋め込み表現(ベクトル)を求める
デコーダ:翻訳語の単語列を埋め込まれた文章をインプットとして、次の単語を予測(…らしい)←理解しきれていない
自分での解釈した図(ひどいver)作ってみました。

このような感じで、エンコーダーとデコーダーの積み重ねと結び付けから構成されている。
(論文中での6という数字には特別な意味は込められておらず、変更可能だとのこと)。
エンコーダ: N=6層で構成、6層とも同じ構造。
- 各層は Multi-Head Attention層 と Position-wise全結合層 (FNN)の2つのサブ層で構成
- それぞれの後には Add & Normがある
デコーダ: N=6 層で構成、6層とも同じ構造。
- エンコーダーにエンコーダの出力を受け取るMulti-Head Attention層を追加した形
- デコーダの1つ目は図に書いてある通りMasked Multi-Head Attentionに
(対象単語より時系列的に未来方向にAttentionが加わらないようにしている。翻訳タスクでカンニングを防ぐ。)
※Add & Norm=“残差結合(skip connection) + 正規化層”
各ブロックの説明
以下のブロックで構成され、分かればモデル構造がだいたい理解できる。
- エンコーダ-デコーダモデル
- Attention
- Position-wise全結合層(Position wise FFN)
- 文字の埋め込み (Input enbedding,output embedding)
- 位置エンコーディング(Position encoding)
- Add & Norm=skip connection + 正規化層”
- ソフトマックス
エンコーダ-デコーダモデル

エンコーダが入力データを処理して符号化(エンコード)し、符号化された情報をデコーダの方で複元(デコード)する形状のモデルとなっている。
AutoEncoderを想像していただけると分かりやすいと思いますが、まず特徴量にエンコーダが変換し(圧縮し)、デコーダーは復元として出力する。そうすることによって過去のデータを参照し、データを変形することができる(※イメージです)。
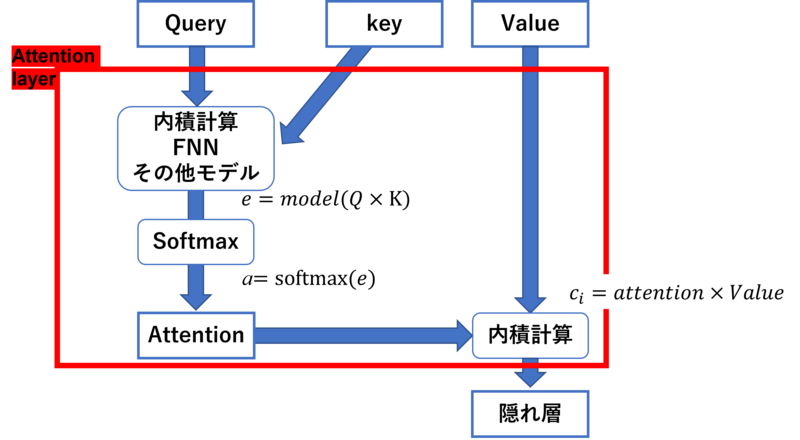
Attention
Attention機構

Qがquery、Kがkey、Vがvalue
qureryとは検索対象の単語で、key-valueがある意味答えになる単語のkeyとその値になり、queryからkey-valueに注意を向けるイメージとなる。
Attentionは、queryがmemoryから必要な情報を持ってくるイメージ
memory から情報を引っ張ってくるときには、 query は key によって注目すべき箇所=attentionとする。
$$
attention=softmax(\tfrac{QK^{T}}{\sqrt{d_{model}}})
$$
その重みを加味して Value から情報を抽出する。
$$
c=attenntion\times V
$$
※Multi-Head Attentionは上記のattentionを複数並べることにより、精度の向上を図る
self-Attention
自分自身のどの部分が重要かを判断するSelf-Attentionを使います。
つまり、QもKもVも自分自身で、すべて同じ前の層からのアウトプットです。
詳細は前の記事で
#################
Multi-Head Attention

Transformerでは8個の並列計算を行い(h=8)、結合時はベクトルをConcat。
それぞれ異なる情報をエンコードでき、1つでは取りこぼしてしまう情報も十分にカバーすることができ、精度向上が見込める。
エンコーダのself-attention

自分自身のどの部分が重要かを判断するSelf-Attention、すべて同じ前の層からのアウトプットです。
デコーダのself-attention

使うべきでない情報にマスクをかけたMasked Self-Attention。
対象単語より時系列的に後方向にAttentionが加わらないようにしている。時系列の際には、$i$番目の翻訳語の単語を予測する際は、$i-1$番目までの情報しか使うべきではないためである。
エンコーダ→デコーダのAttention

- key、valueは“注意をどこに向ける”なのでエンコーダーのアウトプットを使用
- queryは“注意をどこから向けるか”なので、デコーダーにおける前の層のアウトプットを使用
queryの単語からkey-valueのどの部分に注意を向けるか、ということを学習する。
Position-wise全結合層(Position wise FFN)

各ブロックのAttention層のあとに入っているPosition-wise 順伝播ネットワーク(FNN)。
Position-wiseというのはただ単に、各単語ごとに独立してニューラルネットワークがあることを示すらしい(ただし、重みは共有)。他単語との干渉はない。2層のニューラルネットワークになっている。
$$
FNN(x) = max(0,xW_{1}+b_{1}) W_{2}+b_{2}
$$
※活性化関数はReLUのレイヤー+正則化層
文字の埋め込み (Input enbedding,output embedding)

入力の単語は事前訓練済みの単語分散表現を使ってベクトルに変換する。
↓
インプットとなる単語からembeddingレイヤーを通して、単語の埋め込み表現に変換
位置エンコーディング(Position encoding)

単語の位置関係を捉えられる再帰(recurrence)や畳み込み(convolution)を使っていないため、このままだと単語の順番は関係なくなってしまっている。もはやその概念すらない状態である…
↓
そこで登場するのが、位置エンコードという考え方。単語の位置を考慮した埋め込み表現を作成する。
↓
一番最初にこのモデルに単語の分散表現を入力するときに単語位置に一意の値を各分散表現に加算するの原理。
=以下の式でPositional Encodingを計算し、単語の埋め込み表現に足します。
単語の位置に一意の値を与えてくれるsin関数とcos関数のパターンも学習し、結果として位置の関係・順番を捉える算段になっている。
$$
PE_{(pos.2i)} = sin(pos/10000^{2i/d_{model}})
$$
$$
PE_{(pos.2(i+1))} = cos(pos/10000^{2i/d_{model}})
$$
- $pos$:単語列の何番目
- $i$:埋め込み表現の何番目の次元か?(index)
Add & Norm=skip connection+ 正規化層

skip connection
画像認識で画期的な成果を残したResNetで使われた方法で、更に深いネットワークを実現するために考えられ「層を飛び越えた結合」を加えることである。
Skip connectionを導入することにより、
- 層が深くなっても、層を飛び越える部分は伝播しやすくなる。
- 様々な形のネットワークのアンサンブル学習になっている。
Multi-Head Attentionへのインプットと、 Multi-Head Attentionのアウトプットをインプットとして足し、attentionレイヤーの存在によりパフォーマンスが悪化するようであれば、attentionレイヤーのアウトプットをゼロにするように学習されるので、パフォーマンスの悪化を防ぐ工夫である。計算式は省略。
レイヤー正規化(Layer Normalization)
単にアウトプットの正規化を行うだけの層である。
ソフトマックス

デコーダの最終出力は、ニューラルネットワークに入力された後、ソフトマックスで一番高い確率を示した単語を出力する
そのニューラルネットワークに使う重みは一番最初の単語の分散表現を使うときの重みと同じものを使用する。
コード
を参考にしました。
前処理まで
from tensorflow.keras.datasets import imdb
# imdb = imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data()
#単語が整数にマッピングされた辞書を取得
word_index = imdb.get_word_index()
# 最初の要素を予約(単語を登録)
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"] = 0
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # 不明な単語
word_index["<UNUSED>"] = 3
# 整数を単語にマッピングする辞書を作成
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
import pandas as pd
train_df=pd.DataFrame(train_data)[0].map(decode_review).reset_index(drop=True)
test_df=pd.DataFrame(test_data)[0].map(decode_review).reset_index(drop=True)
# all_df=pd.concat([train_df,test_df])[::10].reset_index(drop=True)
# all_dfimport re
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
#nltk.download('wordnet')
#nltk.download('omw-1.4')
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
import nltk
from nltk.corpus import stopwords
# nltk.download('stopwords')
def clean_text(x):
#ノイズ除去
soup = BeautifulSoup(x, 'html.parser')
text= soup.get_text()
#アルファベット以外をスペースに置き換え
text_ = re.sub(r'[^a-zA-Z]', ' ', text)
#単語長が短いものものは削除(中身による)+その後の処理のために分割
text_ = [word for word in text_.split() if len(word) > 2]
#形態素=>動詞
text_ = [lemmatizer.lemmatize(word.lower(), pos="v") for word in text_]
#ステミング
# text_ = [stemmer.stem(word) for word in text_]
#stopword除去
A = [word for word in text_ if word not in stopwords.words('english')]
#単語同士をスペースでつなぎ, 文章に戻す
#その後の処理で戻す必要ない場合はコメントアウト
clean_text = ' '.join(A)
return clean_text
#軽くするために10個飛ばし
clean_text_df=train_df[::10].map(clean_text)
clean_text_df
clean_text_test_df=test_df[::10].map(clean_text)
clean_text_test_df
clean_text_df=train_df[::10].map(clean_text)
clean_text_df
clean_text_test_df=test_df[::10].map(clean_text)
clean_text_test_df配列のid化
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
all_text=pd.concat([train_texts,test_texts]).reset_index(drop=True)
sentences = []
for text in all_text:
text_list = text.split(' ')
sentences.append(text_list)
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences)
sequences_tk = tokenizer.texts_to_sequences(sentences)
#pd.DataFrame(sequences_tk)
MAX_SEQUENCE_LENGTH =int(pd.DataFrame(sequences_tk).shape[1])
MAX_SEQUENCE_LENGTH
#要素の合わない配列に対して、0 で埋めるなどして配列のサイズを一致させる。
X=pad_sequences(sequences_tk, maxlen=MAX_SEQUENCE_LENGTH, truncating='post')
X_train=X[:train_texts.shape[0]]
X_test=X[train_texts.shape[0]:]
word_index = tokenizer.word_index
num_words = len(word_index)
print(num_words)
学習
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import optimizers
from tensorflow.keras import regularizers
class TransformerBlock(layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super(TransformerBlock, self).__init__()
self.att = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.ffn = keras.Sequential(
[layers.Dense(ff_dim, activation="relu"), layers.Dense(embed_dim),]
)
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = layers.Dropout(rate)
self.dropout2 = layers.Dropout(rate)
def call(self, inputs, training):
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
class TokenAndPositionEmbedding(layers.Layer):
def __init__(self, maxlen, vocab_size, embed_dim):
super(TokenAndPositionEmbedding, self).__init__()
self.token_emb = layers.Embedding(input_dim=vocab_size, output_dim=embed_dim)
self.pos_emb = layers.Embedding(input_dim=maxlen, output_dim=embed_dim)
def call(self, x):
maxlen = tf.shape(x)[-1]
positions = tf.range(start=0, limit=maxlen, delta=1)
positions = self.pos_emb(positions)
x = self.token_emb(x)
return x + positions
embed_dim = 128 # Embedding size for each token
num_heads = 8 # Number of attention heads
ff_dim = 128 # Hidden layer size in feed forward network inside transformer
inputs = layers.Input(shape=(maxlen,))
embedding_layer = TokenAndPositionEmbedding(maxlen, vocab_size, embed_dim)
x = embedding_layer(inputs)
transformer_block = TransformerBlock(embed_dim, num_heads, ff_dim)
x = transformer_block(x)
x = layers.GlobalAveragePooling1D()(x)
x = layers.Dropout(0.1)(x)
x = layers.Dense(64, kernel_regularizer=regularizers.l1_l2(l1=0.01, l2=0.01), activation="relu")(x)
x = layers.Dropout(0.1)(x)
outputs = layers.Dense(2, activation="softmax")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
# Preparing callbacks.
adam=optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(optimizer=adam,
loss='sparse_categorical_crossentropy',
metrics=['acc'])
callbacks = [
EarlyStopping(patience=10)
]
seed_everything(42)
# Train the model.
history=model.fit(x=X_train,
y=train_label,
batch_size=64,
epochs=100,
validation_split=0.2,
callbacks=callbacks,
shuffle=True)
hist_df = pd.DataFrame(history.history)
# 可視化
plt.figure()
hist_df[['acc', 'val_acc']].plot()
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.show()
plt.figure()
hist_df[['loss', 'val_loss']].plot()
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()学習まで行ってみてください!このコードでだいたい約83~84%になると思います。
ここまでやっての感想
トピックモデル→ニューラルネットワーク系→Transformer→.…と無限に勉強することは連鎖すると思いました。
ChatGPTについて
大規模言語モデル等の台頭により、新しい技術を取り入れることも大事になっていると考えているため、最近学んだChatGPTでどういう文章を送ればよい答えが返ってくるかということをまとめてみました。

トピックモデル系


ニューラルネットワークモデル系



古典的なところから順々に技術が進歩し今があると思うので、基本に立ち返るのも大事なのかなって思いました。精度に関しても古典的な方が高い場合もありますし、単純に知識として役に立つと思います。
是非、参考にしてみてください。
まとめ
まとめを書くのを忘れていたので後日記載します(2022/09/27 1:31)
もし、この記事を読んで参考になった・他の記事も読んでみたいと思った方、twitterのフォローボタンを押していただけるとモチベーション向上につながるので、よろしくお願いいたします。

コメント