
「自然言語処理ってなに?」「何から始めればいい?」といったお悩みを解決できるかもしれない記事になっています。 自然言語処理に対して無知すぎた自分が、bertを学ぶ前に、ニューラルネットワーク系でテキスト分類をしたいとおもった際に学んだことをまとめてみました。
RNNに関して
必要なライブラリ
- sklearn
- numpy
- pandas
- BeautifulSoup
- gensim
- nltk
- tensorflow==2.5.0
リカレントニューラルネットワーク:RNN

概要
「再帰型ニューラルネットワーク」と呼ばるもので、時系列データや音声データなどの過去の情報が大事になってくるようなデータに強力なモデルとなっている。
過去に入力された単語列から次に来る単語を予測するなどのパターンを認識するように設計されたニューラルネットワークのモデルともいえる。
<特徴>
テキストや音声などの入出力が可変長の系列データを扱う場合、通常のNNは固定長に変換する場合が多く、情報が失われがちである。
↓
RNNは、可変長の入力を扱える+入力系列の要素間に存在する依存性を扱うことができる
※それまでに入力された系列を考慮した予測が可能
入力系列の要素間に存在する依存性を見るために、過去に入力された系列の情報を保持する機能である、「隠れ状態」(hidden state)をもつ。
※隠れ状態は固定長で、過去に入力した系列の情報が圧縮されいている。
時点tでの隠れ状態$h_t$は1つ前の時点における隠れ状態$h_{t-1}$と現在の入力$x_t$で計算する。最もシンプルなRNNはtanh層1つでできている。以下にイメージ図を載せる。


時間軸に沿ったデータを古い順に入力し。逆伝搬する誤差も過去に遡って反映するため、勾配降下法を用いるが、時間軸に沿って誤差を反映するため、BackPropagation Through-Timeと呼ばれてもいる。
コード データのロード 前処理等
データセットをダウンロードし、データフレームに成形(他でもよくデータフレームを用いるため)。
word_index = imdb.get_word_index()
# 最初の要素を予約(単語を登録)
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"] = 0
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # 不明な単語
word_index["<UNUSED>"] = 3
# 整数を単語にマッピングする辞書を作成
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
import pandas as pd
train_df=pd.DataFrame(train_data)[0].map(decode_review).reset_index(drop=True)#データを軽くするため
test_df=pd.DataFrame(test_data)[0].map(decode_review).reset_index(drop=True)#データを軽くするためデータセットのテキストに対して前処理を行う。
from bs4 import BeautifulSoup
import re
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
#nltk.download('wordnet')
#nltk.download('omw-1.4')
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
import nltk
from nltk.corpus import stopwords
# nltk.download('stopwords')
def clean_text(x):
#ノイズ除去
soup = BeautifulSoup(x, 'html.parser')
text= soup.get_text()
#アルファベット以外をスペースに置き換え
text_ = re.sub(r'[^a-zA-Z]', ' ', text)
#単語長が短いものものは削除(中身による)+その後の処理のために分割
text_ = [word for word in text_.split() if len(word) > 2]
#形態素=>動詞
text_ = [lemmatizer.lemmatize(word.lower(), pos="v") for word in text_]
#ステミング
# text_ = [stemmer.stem(word) for word in text_]
#stopword除去
A = [word for word in text_ if word not in stopwords.words('english')]
#単語同士をスペースでつなぎ, 文章に戻す
#その後の処理で戻す必要ない場合はコメントアウト
clean_text = ' '.join(A)
return clean_text
clean_text_df=train_df.map(clean_text)
clean_text_df
clean_text_test_df=test_df.map(clean_text)
clean_text_test_df
#テストで実行するため5こと飛ばしデータを用いて軽量で実行する
diff=5
train_texts=clean_text_df.iloc[::diff]
train_label=train_labels[::diff]
test_texts=clean_text_test_df.iloc[::diff]
test_label=test_labels[::diff]
np.shape(train_texts),np.shape(train_label),np.shape(test_texts),np.shape(test_label)コード(2値分類) RNN
配列のid化(トークン化)を行う。
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
all_text=pd.concat([train_texts,test_texts]).reset_index(drop=True)
sentences = []
for text in all_text:
text_list = text.split(' ')
sentences.append(text_list)
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences)
#テキストデータを数値化
sequences_tk = tokenizer.texts_to_sequences(sentences)
MAX_SEQUENCE_LENGTH =int(pd.DataFrame(sequences_tk).shape[1])
MAX_SEQUENCE_LENGTH
#要素の合わない配列に対し、0で埋めるなどの配列のサイズを一致させる処理
X=pad_sequences(sequences_tk, maxlen=MAX_SEQUENCE_LENGTH, truncating='post')
X_train=X[:train_texts.shape[0]]
X_test=X[train_texts.shape[0]:]RNNの構築と学習を行う。
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense,Input,Embedding,SimpleRNN, GlobalMaxPooling1D
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.metrics import f1_score, precision_score, recall_score
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Embedding
from tensorflow.keras.layers import InputLayer
from tensorflow.keras import optimizers
from tensorflow.keras import layers
from tensorflow import keras
from tensorflow.keras import regularizers
word_index = tokenizer.word_index
num_words = len(word_index)
print(num_words)
input_dim = num_words+1 # 入力データの次元数:単語数いれればいい?(把握しきれていない…)
emb_dim = 300
output_dim = 2 # 出力データの次元数:クラス分
num_hidden_units = 64 # 隠れ層のユニット数
batch_size = 128 # ミニバッチサイズ
epochs = 100 # 学習エポック数
def RNN_model():
model = Sequential()
model.add(InputLayer(input_shape=(None,), name='input'))
# Embeddingによりベクトルを変換する
model.add(Embedding(
input_dim=input_dim, # 入力として取り得るカテゴリ数(パディングの0を含む)# vocabulary_size
output_dim=emb_dim, # 出力ユニット数(本来の特徴量の次元数)
# weights=[embedding_matrix], # 埋め込み行列を指定
trainable=True, # 埋め込み行列を固定(学習時に更新)
mask_zero=True)) # 0をパディング用に特別扱いする
#ここがRNN層である。
model.add(SimpleRNN(
num_hidden_units,
return_sequences=False,name="rnn"))
model.add(Dense(100, kernel_regularizer=regularizers.l1_l2(l1=0.01, l2=0.01), activation="relu"))
model.add(layers.Dropout(0.25))
model.add(Dense(output_dim, activation="softmax"))
adam=optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(optimizer=adam,
loss='sparse_categorical_crossentropy',
metrics=['acc'])
model.summary()
return model
# Preparing callbacks.
model=RNN_model()
callbacks = [
EarlyStopping(patience=3)
]
seed_everything(42)#seed値を固定にするもの:しらべてみてね
# Train the model.
history=model.fit(x=X_train,
y=train_label,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2,
callbacks=callbacks,
shuffle=True)評価をする。
hist_df = pd.DataFrame(history.history)
# 可視化
plt.figure()
hist_df[['acc', 'val_acc']].plot()
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.show()
plt.figure()
hist_df[['loss', 'val_loss']].plot()
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()

from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
predict=np.argmax(model.predict(X_test),axis=1)
accuracy_score(test_label,predict),f1_score(test_label,predict)(0.765, 0.7792598158932934)
コード(2値分類) RNN+埋め込み層
パラメータは上と同じのを用いる。
input_dim = num_words+1 # 入力データの次元数:実数値1個なので1を指定
emb_dim = 300
output_dim = 2 # 出力データの次元数:クラス分
num_hidden_units = 64 # 隠れ層のユニット数
batch_size = 128 # ミニバッチサイズ
epochs = 100 # 学習エポック数
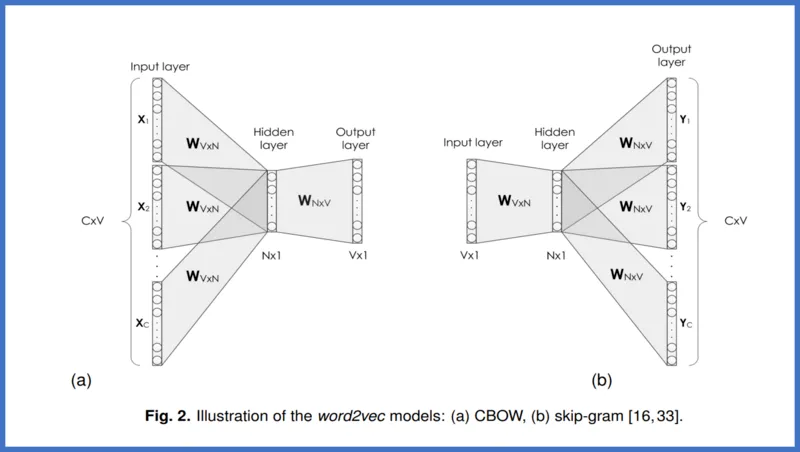
ここで、単語ベクトルとしてword2vecの学習済みモデルである”GoogleNews-vectors-negative300”を用いてみる。(自作しても可)
自作する際にはこの記事等を参考にしてください。

import gensim
googlenews_w2v = gensim.models.KeyedVectors.load_word2vec_format('./w2v_model/GoogleNews-vectors-negative300.bin.gz', binary=True)
googlenews_w2vembedding_matrixを作製する。
#使ったw2vモデルが300列
#(単語数,300)次元のゼロ行列をあらかじめ作成)
word_index = tokenizer.word_index
num_words = len(word_index)
vec_model=googlenews_w2v
embedding_matrix = np.zeros((num_words+1, 300))
for word, i in word_index.items():
# if word in vec_model.wv.index_to_key:
if word in vec_model.index_to_key:
# embedding_matrix[i] = vec_model.wv[word]
embedding_matrix[i] = vec_model[word]embedding_matrixを活用したRNNモデルを作製。
def RNN_wv_model():
model = Sequential()
model.add(InputLayer(input_shape=(None,), name='input'))
# Embeddingによりベクトルを変換する
model.add(Embedding(
input_dim=embedding_matrix.shape[0],# 入力として取り得るカテゴリ数(パディングの0を含む)
output_dim=emb_dim, # 出力ユニット数(本来の特徴量の次元数)
weights=[embedding_matrix], # 埋め込み行列を指定
trainable=True, # 埋め込み行列を固定(学習時に更新)
mask_zero=True)) # 0をパディング用に特別扱いする
model.add(SimpleRNN(
num_hidden_units,
return_sequences=False,name="rnn"))
model.add(Dense(100, kernel_regularizer=regularizers.l1_l2(l1=0.01, l2=0.01), activation="relu"))
model.add(layers.Dropout(0.25))
model.add(Dense(output_dim, activation="softmax"))
adam=optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(optimizer=adam,
loss='sparse_categorical_crossentropy',
metrics=['acc'])
model.summary()
return model
学習を実行
# Preparing callbacks.
model=RNN_wv_model()
callbacks = [
EarlyStopping(patience=3)
]
seed_everything(42)#seed値を固定にするもの:しらべてみてね
# Train the model.
history=model.fit(x=X_train,
y=train_label,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2,
callbacks=callbacks,
shuffle=True)結果がどうなるかは、実際に動かして試してみてください!
まとめ
word2vecの使い方やRNNについて何となくでも学べましたでしょうか?
次回はRNNの改善版?のLSTMについて学びます。
もし、この記事を読んで参考になった・他の記事も読んでみたいと思った方、twitterのフォローボタンを押していただけるとモチベーション向上につながるので、よろしくお願いいたします。
ChatGPTについて
大規模言語モデル等の台頭により、RNNなどを学ぶことも大事ですが新しい技術を取り入れることも大事になっていると考えているため、最近学んだChatGPTでどういう文章を送ればよい答えが返ってくるかということをまとめてみました。

コメント