
「自然言語処理ってなに?」「何から始めればいい?」といったお悩みを解決できるかもしれない記事になっています。 自然言語処理に対して無知すぎた自分が、まず基本的な手法の一種であるトピックモデルを学んだ後に、単語を推論ベースでベクトル化する手法word2vecについて学んでみました。
www.scielo.org.mx
より一部引用、および勉強させていただきました。
必要なライブラリ
- sklearn
- numpy
- pandas
- BeautifulSoup
- gensim
- nltk
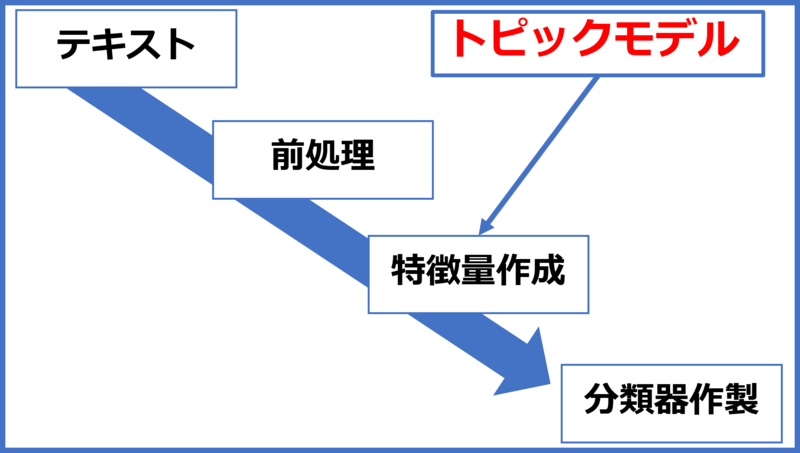
ベクトル表現の種類
主にカウントベースと推論ベースが存在する。
カウントベース
単語の出現回数による文章のベクトル化
- BoW
- TF-IDF
- LSI
など
推論ベース
単語の分散表現を用いた手法
単語の分散表現とは、、、
- 単語を固定長のベクトルで表現することを「単語の分散表現」と呼びます。
- 単語をベクトルで表現することができれば単語の意味を定量的に把握することができるため、様々な処理に応用することができます。
推論ベースにおける主要な考え方
- 「単語の意味は周囲の単語によって形成される」というアイデアに基づく分布仮説が採用されている
代表: Word2Vec
ニューラルネットワークによる学習を行い、以下の特徴がある。
- 文章や単語を意味のベクトルで表現できる
- 分布仮説:前後の文脈から、ある単語と一緒に使用されやすい単語の確率を推定
- 埋め込むことで意味を表現可能→RNN等で用いる
- 単語同士での足し算や引き算などができる
word2vec
Word2vecでは下記2つのモデルが使用されています。
- CBOW(continuous bag-of-words)
- skip-gram
それぞれのモデルの仕組みについて説明していきます。
CBOW
文脈からターゲットを推測することを目的とする教師あり学習
前後1単語から前後の文脈をどの程度利用するかはモデル作成ごとに判断する。
この場合の入力は周辺語、出力は中心語
画像作成が下手で申し訳ございません。もっといい画像がネット上にあるので参考にしてください。

CBOWモデルは出力層において各単語のスコアに対してSoftmax関数を適応することで「確率」を得ることができる。
※確率は前後の単語を与えた時にその中央にどの単語が出現するのかを表します
CBOWの学習では正解ラベルとニューラルネットワークが出力した確率の交差エントロピー誤差を求め、それを損失としてその損失を少なくしていく方向に学習を進めます。
skip-gram
中心のある単語から周辺の単語を予測する教師あり学習
中央の単語から前後の複数の文章を予測するモデル
こちらに関しても画像作成が下手で申し訳ございません。もっといい画像がネット上にあるので参考にしてください。

skip-gramの入力層はひとつで出力層はデータセット内の文章の数だけ存在し、それぞれの出力層で個別に損失を求め、それらを足し合わせたものを最終的な損失となる。
比較
CBOWとskip-gram
- CBOWとskip-gramではskip-gramモデルの方が良い結果が得られるとされており、コーパスが大規模になるにつれて程頻出の単語や類推問題の性能の点において優れた結果が得らるとのことです。
- 一方、skip-gramは文章の数だけ損失を求める必要があるため学習コストが大きく、CBOWの方が学習は高速です。
pythonとgensimを用いたコード
モデル作製
input_dataset=clean_text_df.values
texts = [
[w for w in doc.lower().split() if w not in stopwords.words('english')]
for doc in input_dataset
]
texts
from gensim.models import word2vec
seed_everything(42)
#sg:1ならskip-gramで0ならCBOWで学習
#size 何次元の分散表現を獲得するかを指定
#window 前後の単語数を指定
#min_count 指定の数以下の出現回数の単語は無視
model=word2vec.Word2Vec(texts,sg=1,vector_size=100,window=5,min_count=1 ,epochs=100, seed=42, workers=1)作製したモデルで類似した単語を探す
for i in model.wv.most_similar('business'):
print(i)- (‘contractors’, 0.6177799105644226)
- (‘competitor’, 0.591386616230011)
- (‘meeuwsen’, 0.5839970707893372)
- (‘holdup’, 0.5756336450576782)
- (‘bahiyyaji’, 0.559677004814148)
- (‘sunways’, 0.5592241287231445)
- (‘collectibles’, 0.5480270981788635)
- (‘piers’, 0.5407338738441467)
- (‘malignancy’, 0.534362256526947)
- (‘koolhoven’, 0.5312635898590088)
作製したモデルで単語同士の演算
# 単語の足し算、引き算は positive, negative で引数指定
model.wv.most_similar(positive=["business", "consultant"], negative=["data"], topn=1)[(‘venue’, 0.46294716000556946)]
作製したモデルで単語同士の類似度を確認
# 二つの単語の類似度を得る
print(model.wv.similarity("business", "consultant"))0.14571999
あとがき
RNNやLSTMなどに組み込んで使ったりします。
RNN等についてまとめる際にはword2vecの入れ方もまとめてみます。
もし、この記事を読んで参考になった・他の記事も読んでみたいと思った方、twitterのフォローボタンを押していただけるとモチベーション向上につながるので、よろしくお願いいたします。
ChatGPTについて
大規模言語モデル等の台頭により、word2vecはなかなか学ばなくなってしまった気もしますので、最近学んだChatGPTでどういう文章を送ればよい答えが返ってくるかということをまとめてみました。

コメント