
「自然言語処理ってなに?」「何から始めればいい?」といったお悩みを解決できるかもしれない記事になっています。 自然言語処理に対して無知すぎた自分が、BERTを学ぶ前に、まず基本的な手法の一種であるトピックモデルを学び、使えるようになりたいと思い、まとめたことを解説します。
この記事は1~3までのまとめのような記事です。まず初めにそちらを読んでからの方が理解はしやすいかもしれません。コードのコピーだけならこの記事のみでも大丈夫です。
※この記事を読む前に、以下のその1~3に目を通していただけると、この記事のテーマをよりご理解いただけると思います。
★その1

★その2

★その3
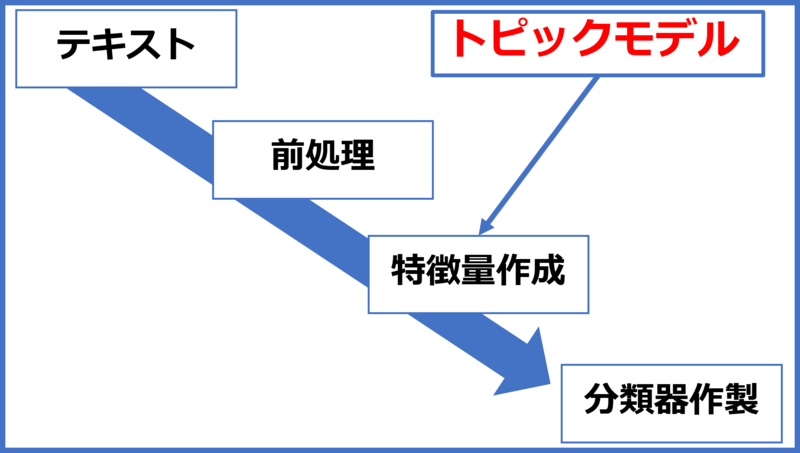
トピックモデルを用いたテキスト分類の流れ
必要なライブラリ
- sklearn
- numpy
- pandas
- BeautifulSoup
- gensim
- nltk
分類までのコードを一挙に載せます。
前処理
データのインポート等は前回のとおりなので省略します。
データの前処理とtrain,testの学習に用いるものをまとめます。
import pandas as pd
train_df=pd.DataFrame(train_data)[0].map(decode_review)[::].reset_index(drop=True)#データを軽くするため
test_df=pd.DataFrame(test_data)[0].map(decode_review)[::5].reset_index(drop=True)#データを軽くするため
clean_text_df=train_df.map(clean_text)
clean_text_df
clean_text_test_df=test_df.map(clean_text)
clean_text_test_df
train_texts=clean_text_df
train_label=train_labels[::]
test_texts=clean_text_test_df
test_label=test_labels[::5]
np.shape(train_texts),np.shape(train_label),np.shape(test_texts),np.shape(test_label)一括に処理したいものもあるため、結合しておく。
all_df=pd.concat([train_texts,test_texts]).reset_index(drop=True)
all_df特徴量作製
複数の変換器を適用し、結果をaxis=1(横軸)方向に連結できるFeatureUnionを使用してみました。今回初めて使ってみたものなので詳しい仕様については勉強中です。
from sklearn.pipeline import FeatureUnion
from sklearn.feature_extraction.text import TfidfVectorizer
#FeatureUnion
vectorizers = [
('tfidf', TfidfVectorizer(max_df=0.90, min_df=2, max_features=2000, stop_words='english')),
('count', CountVectorizer(max_df=0.90, min_df=2, max_features=2000, stop_words='english'))
]
vectorizer = FeatureUnion(vectorizers)
vectorizer.fit(all_df)
train_union=vectorizer.transform(train_texts).toarray()
test_union=vectorizer.transform(test_texts).toarray()LDAとLSIを特徴量として作成します。
input_dataset=train_texts.values
texts = [
[w for w in doc.lower().split() if w not in stopwords.words('english')]
for doc in input_dataset
]
import collections
import gensim
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
#一部の分析には不必要な単語を除去するための以下
count = collections.Counter(w for doc in texts for w in doc)
tokens_num = len(count.most_common())
N = int(tokens_num *0.01)
max_freq = count.most_common()[N][1]
#出現回数が上位1%以上や5回以下の単語を除去
corpus = [[w for w in doc if max_freq > w[1] >= 5] for doc in corpus]
num_topics = 20
lsi = gensim.models.LsiModel(
corpus=corpus,
num_topics=num_topics,
id2word=dictionary,
random_seed=42
)
num_topics = 20
lda = gensim.models.ldamodel.LdaModel(
corpus=corpus,
num_topics=num_topics,
id2word=dictionary,
random_state=42
)LDAやLSIの結果を一括でdataframeに反映させるためのコードを作りました。作った後に、もっときれいに書けたと後悔しております。
def use_topic(x,model):
new_doc=x.split()
new_doc_bow = dictionary.doc2bow(new_doc)#学習済みの辞書で作製
lda_pre=model[new_doc_bow]
pre_list=[]
num=0
for i in range(0,num_topics):
if num < len(lda_pre):
if lda_pre[num][0] ==i:
# print(lda_pre[num])
pre_list.append(lda_pre[num][1])
num+=1
else:
# print((i,0))
pre_list.append(0)
else:
# print((i,0))
pre_list.append(0)
return pre_list
def topic_df(df,model,name):
topic_list=[]
for i in df:
topic_list.append(use_topic(i,model))
to_col=[name+"_"+str(i) for i in range(num_topics)]
to_df=pd.DataFrame(topic_list,columns=to_col)
return to_df
実際に使用して特徴量を作製する。
#lda
df=train_texts
model=lda
name="lda"
train_lda_df=topic_df(df,model,name)
train_lda_df
df=test_texts
model=lda
name="lda"
test_lda_df=topic_df(df,model,name)
test_lda_df
#lsi
df=train_texts
model=lsi
name="lsi"
train_lsi_df=topic_df(df,model,name)
train_lsi_df
df=test_texts
model=lsi
name="lsi"
test_lsi_df=topic_df(df,model,name)
test_lsi_df
#LSIは負もとってしまうので、0以上の分布に強制変換させた
from sklearn import naive_bayes, metrics, preprocessing
lsi_df=pd.concat([train_lsi_df,test_lsi_df])
mms=preprocessing.MinMaxScaler()
lsi_df_mms=pd.DataFrame(mms.fit_transform(lsi_df),columns=lsi_df.columns)
train_lsi=lsi_df_mms.iloc[:25000]
test_lsi=lsi_df_mms.iloc[25000:].reset_index(drop=True)以下はtfidfバージョンなので説明は省略します。
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
tfidf = gensim.models.TfidfModel(corpus)
corpus_tfidf=tfidf[corpus]
#一部の分析には不必要な単語を除去するための以下
count = collections.Counter(w for doc in texts for w in doc)
tokens_num = len(count.most_common())
N = int(tokens_num *0.01)
max_freq = count.most_common()[N][1]
#出現回数が上位1%以上や5回以下の単語を除去
corpus = [[w for w in doc if max_freq > w[1] >= 5] for doc in corpus]
num_topics = 20
lda_tfidf=gensim.models.ldamodel.LdaModel(
corpus=corpus_tfidf,
num_topics=num_topics,
id2word=dictionary,
random_state=42
)
num_topics = 20
lsi_tfidf=gensim.models.lsimodel.LsiModel(
corpus=corpus_tfidf,
num_topics=num_topics,
id2word=dictionary,
random_seed=42
)
df=train_texts
model=lda_tfidf
name="lda_tfidf"
train_lda_tfidf_df=topic_df(df,model,name)
# train_lda_df
df=test_texts
model=lda_tfidf
name="lda_tfidf"
test_lda_tfidf_df=topic_df(df,model,name)
# test_lda_df
df=train_texts
model=lsi_tfidf
name="lsi_tfidf"
train_lsi_tfidf_df=topic_df(df,model,name)
# train_lsi_df
df=test_texts
model=lsi_tfidf
name="lsi_tfidf"
test_lsi_tfidf_df=topic_df(df,model,name)
# test_lsi_df
lsi_tfidf_df=pd.concat([train_lsi_tfidf_df,test_lsi_tfidf_df])
mms=preprocessing.MinMaxScaler()
lsi_tfidf_df_mms=pd.DataFrame(mms.fit_transform(lsi_tfidf_df),columns=lsi_tfidf_df.columns)
train_lsi_tfidf=lsi_tfidf_df_mms.iloc[:25000]
test_lsi_tfidf=lsi_tfidf_df_mms.iloc[25000:].reset_index(drop=True)※MinMaxScaleする軸を間違えてる可能性あり…
学習(層化交差検証を用いた)
作製した特徴量等をまとめて学習できるようにする。
X_train=pd.concat([pd.DataFrame(train_union),train_lda_df,train_lsi,train_lda_tfidf_df,train_lsi_tfidf],axis=1).values
X_test=pd.concat([pd.DataFrame(test_union),test_lda_df,test_lsi,test_lda_tfidf_df,test_lsi_tfidf],axis=1).values
y_train=train_label
y_test=test_label
今回はnaive_bayes.MultinomialNBを用いて学習してみます。交差検証も行っているため、見本にはなると思います。naive_bayes.MultinomialNBを用いましたが、SVMやxgboostなども使ってみてもいいと思います。
from sklearn import naive_bayes, metrics, preprocessing
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import f1_score
from sklearn.metrics import accuracy_score
split_num=5
kf = StratifiedKFold(n_splits=split_num, shuffle=True, random_state=42)
valid_scores = []
model_MNB = []
for fold, (train_indices, valid_indices) in enumerate(kf.split(X_train,y_train)):
X_train_, X_valid_ = X_train[train_indices], X_train[valid_indices]
y_train_, y_valid_ = y_train[train_indices], y_train[valid_indices]
#naive_bayes.MultinomialNBを使用
clf = naive_bayes.MultinomialNB(alpha=0.2, fit_prior='True' )
#学習を行う
clf.fit(X_train_, y_train_)
y_val_pred = clf.predict(X_valid_)
score = f1_score(y_valid_,y_val_pred)
print(f'fold {fold} f1: {score}')
print(accuracy_score(y_valid_,y_val_pred))
valid_scores.append(score)
model_MNB.append(clf)
cv_score = np.mean(valid_scores)
print(f'CV score: {cv_score}')
pre_list_MNB=[]
for i in range(split_num):
pre_list_MNB.append(model_MNB[i].predict(X_test))
prediction_MNB=scipy.stats.mode(pre_list_MNB)[0]評価してみます。
from sklearn.metrics import accuracy_score
accuracy_score(y_test,prediction_MNB[0]),f1_score(y_test,prediction_MNB[0])かなり気楽に学習してみました。結果として、正答率約83%でf1値0.83であったのでなかなか悪くないと思っています。モデルの箇所を書き換えるだけで、学習器を変更できるので試してみるといいと思います。
まとめ
初めてトピックモデルを触れてみましたが、古くから活用されているものも使い方次第ではかなり応用できるのではないでしょうか?
1-3の間でだいぶ理解しつつあったため、この記事の作成及びモデルの作製にはそんな時間かかりませんでした。アクティブラーニングって大事だなって実感しました。
これが誰かの参考になれば幸いです。
もし、この記事を読んで参考になった・他の記事も読んでみたいと思った方、twitterのフォローボタンを押していただけるとモチベーション向上につながるので、よろしくお願いいたします。
ChatGPTについて
大規模言語モデル等の台頭により、トピックモデルはなかなか学ばなくなってしまった気もしますので、最近学んだChatGPTでどういう文章を送ればよい答えが返ってくるかということをまとめてみました。

コメント