
「自然言語処理ってなに?」「何から始めればいい?」といったお悩みを解決できるかもしれない記事になっています。 自然言語処理に対して無知すぎた自分が、BERTを学ぶ前に、まず基本的な手法の一種であるトピックモデルを学び、使えるようになりたいと思い、まとめたことを解説します。
注意)この記事でのトピックモデルの説明はざっくりとしたものです。各詳細が知りたいと思った時は、各工程について調べることをお勧めします。
※この記事を読む前に、以下のその1に目を通していただけると、この記事のテーマをよりご理解いただけると思います。
★その1

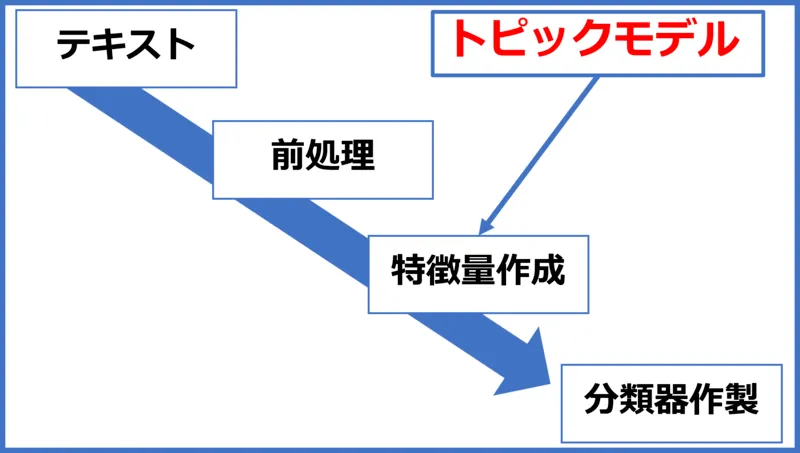
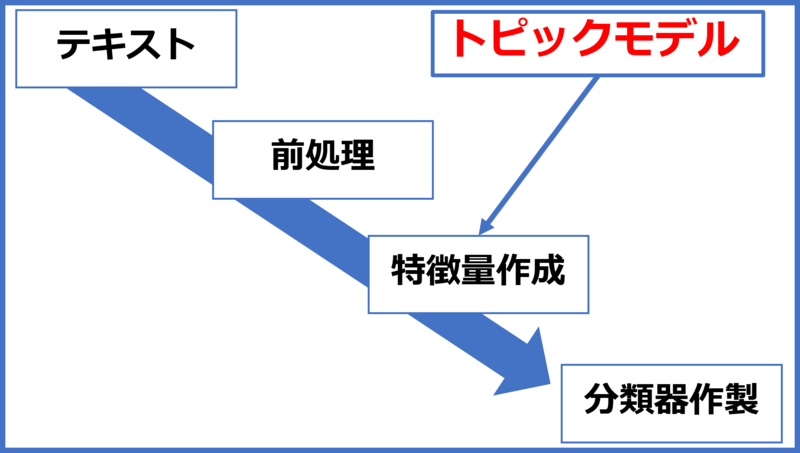
トピックモデルを用いたテキスト分類の流れ
必要なライブラリ
- sklearn
- numpy
- pandas
- BeautifulSoup
- gensim
- nltk
前回までの流れ
前回、テキストの前処理まで行った。今回は、テキストを特徴量にする方法をまとめる。
分類までの流れ
前処理→トピックモデル→分類

前処理
前記事に書きました。
特徴量作成
テキストデータをコンピュータが読める形状に変化させる。
ベクトル化
Bowやtfidfが有名どころ。単語の出現回数による文章のベクトル化をし、コンピュータが読めることができるようにする。
BoW(bag-of-words)+pythonコード
bowは単語の順番を無視してはいるもが、単純に登場した単語の数を文書内で数えあげるもの
from sklearn.feature_extraction.text import CountVectorizer
bow_vectorizer = CountVectorizer(max_df=0.90, min_df=2, max_features=2000, stop_words='english')
bow = bow_vectorizer.fit_transform(てきすとでーたせっと)
print(bow.toarray().shape)tfidf+pythonコード
全文章に対してレアな単語が何回も出てくるようなら、文書を分類する際にその単語の重要度を上げるもので、tfidf=「tfという概念」×「idfという概念」である。
「tf」(Term Frequency):単語の出現頻度
$$
tf=\frac{1文章における単語Xの出現数}{1文章における全単語の出現数の和}
$$
「idf」(Inverse Document Frequency):単語のレア度を示す
$$
idf=\log(\frac{全文章数}{単語Xを含む文章数})+1
$$
「tf-idf」:2つの概念を組み合わせる
$$
tfidf=tf\times idf
$$
「その文書内でどれくらい重要か」を表している。「各文書の単語ごと」に行うことで、文書の特徴がつかみやすくなる。
from sklearn.feature_extraction.text import TfidfVectorizer
tf_idf_vectorizer = TfidfVectorizer(analyzer="word", ngram_range=(1, 3), min_df=1, stop_words="english")
tf_idf_vector = tf_idf_vectorizer.fit_transform(てきすとでーたせっと)
print(tf_idf_vector.toarray())※「文書間の類似度」を計算、特徴的に使用されているキーワードを抜き出すなどに用いることが可能になる。
トピックモデル
「文書が潜在的なトピック(話題)」から生成される」という考え方がベースになっている古典的な統計モデル。
※文書内の各単語はあるトピックが持つ確率分布(トピック分布)に従って出現すると仮定

トピックモデルでは、トピックごとに単語の出現頻度分布を想定することで、トピック間の類似性やその意味を解析でき、分類することや似たような文章を検索できたりと、様々な応用が可能である。
トピックモデルの代表的な2つを以下に示す。
LSI(LSA)
LSI=潜在意味解析と呼ばれる手法
→特徴量を「単語数」から「トピック数」に削減してモデル作成&評価を行う。
→「意味が似ていそうな単語は1つのトピックにまとめる」ことで圧縮するイメージ
- BoW(bag-of-words)やtf-idfを解析する。
- 「文章、単語数」から「トピック数」にするために、「特異値分解(SVD)」をして近似する。任意の行列「文章、単語数」が対角行列を用いると、2つの行列に分解することができる。
- できたモデルを使ってクラスタリングや文書分類をする。

LSI(LSA)をpythonで行う。
テキストデータセットを、リスト内に格納する作業。念のため、ストップワードと小文字化させて入れる用を載せておきます。
import nltk
from nltk.corpus import stopwords
# nltk.download('stopwords')
texts = [
[w for w in doc.lower().split() if w not in stopwords.words('english')]
for doc in テキストデータセット
]BoWでコーパスを作成する。
※コーパスとは、、、
- 自然言語の文章などの使用方法を構造化して大規模に集め、記録したもの
- 言葉を大量に集め、コンピュータで検索できるようにしたデータベース
- 自然言語処理の研究に利用するために、品詞などの言語的な情報も付与しているものも
import collections
import gensim
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts] #list.split()1やmap関数でも可能
#一部の分析には不必要な単語を除去するための以下
count = collections.Counter(w for doc in texts for w in doc)
tokens_num = len(count.most_common())
N = int(tokens_num *0.01)
max_freq = count.most_common()[N][1]
#出現回数が上位1%以上や5回以下の単語を除去
corpus = [[w for w in doc if max_freq > w[1] >= 5] for doc in corpus]LSIモデルを作製する。
num_topics = 8
lsi = gensim.models.LsiModel(
corpus=corpus,
num_topics=num_topics,
id2word=dictionary,
random_seed=42
)
LDA
LDA =(Latent Dirichlet Allocation; 潜在的ディレクリ配分法)
ざっくりというと、
- ディリクレ分布等によって各データが生成されていると仮定
- 「文書を生成する」過程・段階を単語の選択の連続(確率的過程)として考える
- LSIの派生とみなせる…らしい
多数の記事群をインプットし、それぞれの文章を単語に分割して情報化して、各記事の文章情報を「トピック」というものにまとめる。
↓
各文書について「どのトピックに属するか」ということを「確率分布」で予測し生成

上のようなトピックと、トピックを構成している重要な単語群を見ることで、人が各トピックの分野を推定可能になる。
LDAをpythonで行う。
num_topics = 8
lda = gensim.models.ldamodel.LdaModel(
corpus=corpus,
num_topics=num_topics,
id2word=dictionary,
random_state=42
)
分類は次の記事で
加えて、cloudwordや実際のデータセットを利用してみる。
その3のリンクです。

もし、この記事を読んで参考になった・他の記事も読んでみたいと思った方、twitterのフォローボタンを押していただけるとモチベーション向上につながるので、よろしくお願いいたします。
ChatGPTについて
大規模言語モデル等の台頭により、トピックモデルはなかなか学ばなくなってしまった気もしますので、最近学んだChatGPTでどういう文章を送ればよい答えが返ってくるかということをまとめてみました。

コメント