
今回はAttention機構を勉強しています。
Transformerを知りたいと思った際に立ちはだかるAttention機構について色々調べて自分なりにまとめてみました。テキスト分類も行ってみましたので是非見ていってください。
※注意:間違いがあるかもしれません。生暖かく見守っていただけると幸いです。
Attention機構
概要
Attention 機構は、深層学習の最近の根幹部分とも言える仕組みだと思われます。特に自然言語処理などでよく使われると思われる方もいらっしゃるかもしれません。いや、自分はそう思っていました。ですが、入力されたデータのどこに注目すべきか・重要視すべきかを考える仕組みであり、画像認識や時系列データにも応用され、画像認識のAttentionも存在するらしいですが今後勉強しようと思います。
歴史的には、Seq2Seq と呼ばれる自然言語処理などで使用されるRNNのモデルに対して組み込まれ、注目を集めたそうです。組み込まれた理由としては、seq2seq の問題は長い文章への対応が難しいことからきています。単語のとても短い文であっても、100単語あるとても長い文であっても、その意味を固定長の次元ベクトルの中に圧縮しないといけないという仕組みであったために、文章が長くなるほどそのシーケンスの内部表現の次元も大きくなっていくような何らかの仕組みが必要であると考られました。
また、RNNは1つ前の状態と新たな入力から次の状態を計算するだけであり、過去の(BiRNNでは過去と未来の)どの時刻の状態がどれだけ次の状態に影響するかまでは直接求めてはいません。
Attention機構は、この問題に対して、「入力と出力のどの単語が関連しているのか」「どこに注目すべきか」を学習させることで対応し、複数のベクトルがあった時に、どのベクトルを重要視するかも含めて学習させる仕組みになっています。
近年では、機械翻訳のために提案された TransformerやBERTなどの超高性能・高精度で高度なモデルに使用され、様々な自然言語処理のタスクで用いられています。
seq2seq、Transformerで用いられるAttention 機構 原理 (数式含む)
後述事項)
- Seq2Seqなどで付随される形で利用されていたAttention層=異なるデータ間の照応関係を獲得すること
- transformerで用いられるAttention層=入力データ内の単語同士の照応関係情報(類似度や重要度)を獲得すること
であるらしいので、別々に考えた方が良かったかもしれません。また、ransformerではScaled Dot-Product Attentionという仕組みを使うので、すこしだけ異なる構造をしています。
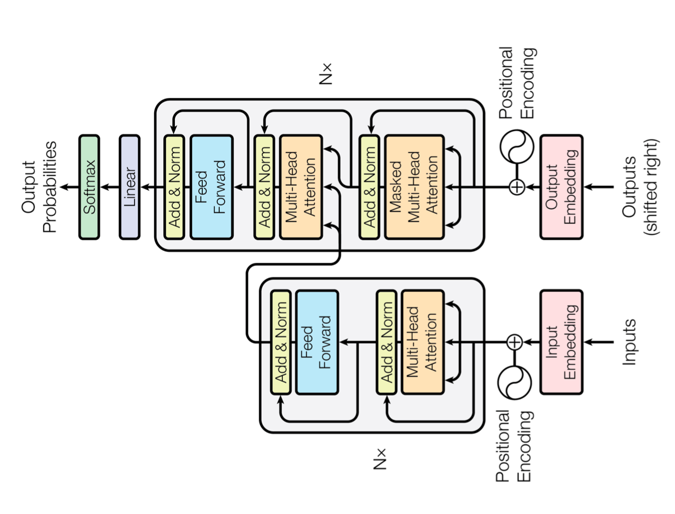
Attention Is All You Need
論文にあった図を自分なりに解釈してみました。
transformerで用いられるもの

seq2seqなどのattention機構

以下はそれに合わせた計算式です。
Transformerで用いられるAttention 機構ではquery, memory(key, value) (以降Q,K,V)で表現していたため、その場合もメモしています。
時刻$i$の出力の隠れ状態$s_i$を計算するときに以下のような処理を行う。
前時刻の出力の内部状態 $s_{i-1}$及び各時刻jの入力$h_j$を入力(QとKを入力)
$$
e_{ij}=a(s_{i-1},h_{j}) → model(Q,K)
$$
※seq2seqではFNNと書いてあった気がします。aの取り方には様々ありますが、一番簡単な方法には単に内積を取るという関数の設定の仕方もあります。これはQの中の各ベクトルと,Kの類似度を計算するブロックです。
次に、$e_{ij}$ を用いて入力の関連度の高さ$α_{ij}$の確率の決定します。これがattenntion!
$$
a_{ij}=softmax_j(e_{ij})
$$
$e_{ij}$の内 $j $に関して一番でかいものだけがほぼ1.0をとり、他はほぼ0になるような関数で、 “注意を向けている場所”を指すものだと思われます。
$α_{ij}$: $i$番目の単語に対して$j$番目の単語が関連している確率もしくは結びつきの強さを表し、そう表現できるように学習する。
※attentionとはQuery で Key を検索して、QueryとKey の類似度が高い部分を注目すべき箇所とし、その重みを加味して Value から情報を抽出するイメージ、だそうです。
そして、$c_i$が i番目の出力に関連度が高い入力の隠れ層の値になる ように学習する。
$$
c_{i} =\sum_{j=1} a_{ij} h_{j} → attenntion\times V
$$
$h_j$は$j$番目の入力の隠れ層の値です。
※attentionにvalueをかけることでvalueの注意による加重平均を取り、注意で加重平均された埋め込み表現・上述のとおり情報を抽出を計算していると思われます。
$c_i$は$i$番目の出力に関連度が高い入力の隠れ層になるため、出力の隠れ層 $s_i$とすると
$$
s_{i}=f(s_{i-1},y_{i-1},c_{i})
$$
$s_{i-1}$:$i-1$番目の隠れ層
$y_i$:$i-1$番目の単語
と導くことができる。
まとめ
従って、まとめると計算過程はこのように行う。
Q(検索クエリ)と memory(K, V)を用いる。
Attention機構は、queryがmemoryから必要な情報を持ってくるイメージである。
↓
memory から情報を引っ張ってくるときには、 query は key によって注目すべき箇所とし、その重みを加味して Value から情報を抽出する
↓
出力の隠れ層に反映させる
実際は、入力とメモリーを結合層(embedding)に入力してから計算。

attention weightの計算に関して
「内積計算・FNN・その他モデル」
scaled dot:$\tfrac{Q^{T}\times K}{\sqrt{d_{model}}}$が主流?transformerではこっちを用いている
加法注意(Additive Attention)と呼ばれるものもあり、その場合はqueryとkeyをFFN(Feed Forward Network)に通してattentionを計算する。。
Self-Attention
文章の埋め込みベクトルを求める手法でYoshua氏らが提案した
input (query:Q) と memory (key:K, value:V) すべてが同じ情報から作製するAttention
- Attention: 入力から,注目すべき場所を見つけるために使用
- Self Attention: 入力を別の表現に変換するために使用

このDENSE層(Embeddingレイヤ)はword2vecのモデルから流用されたりするそうです。分散表現を実現し、固定長埋め込みベクトルに対応づける。
つまり、Q=K=Vである。
Q,K,Vを全て同じテンソルにすることで,Self Attentionではそのテンソルを別のテンソルに変換することが可能になる。
↓
1文の単語たちだけを使って計算するため、単語間の関連度スコア・別のベクトルのようなものに変換することができる
Multi-head-attention
[1706.03762] Attention Is All You Needでは複数attentionを並列計算、結合するため、MultiHeadで複数の潜在表現空間を処理してまとめる方が表現の幅や情報がとれるそう?である。

詳細に関してはもっと勉強してから投稿しようと考えています。
実際にpythonで書いてみたい,,,
CNN+self-attention
tf.keras.layers.Attention | TensorFlow v2.10.0
を参考にテキスト分類をAttention機構をつかっておこなってみたいと考えた。
下の図のような構成の多分self-attenntion?になっているであろう構造のモデルを作製してみた。

input_dim = num_words+1 # 入力データの次元数
emb_dim = 300
output_dim = 2 # 出力データの次元数:クラス分
num_hidden_units = 100 # 隠れ層のユニット数
batch_size = 128 # ミニバッチサイズ
epochs = 100 # 学習エポック数
filters=250 #channel_size
kernel_size=3 #filter size# Variable-length int sequences.
query_input = Input(shape=(None,), name='input_q')
# value_input = Input(shape=(None,), name='input_v')##########selfじゃないとき用
# Embedding lookup.
token_embedding = tf.keras.layers.Embedding(input_dim=input_dim, output_dim=emb_dim,
trainable=True, # 埋め込み行列を固定(学習時に更新)
mask_zero=True) # 0をパディング用に特別扱いする)
# Query embeddings of shape [batch_size, Tq, dimension].
query_embeddings = token_embedding(query_input)
# Value embeddings of shape [batch_size, Tv, dimension].
# value_embeddings = token_embedding(value_input)##########selfじゃないとき用
value_embeddings = token_embedding(query_input)
# CNN layer.
cnn_layer = tf.keras.layers.Conv1D(
filters=filters,
kernel_size=kernel_size,
# Use 'same' padding so outputs have the same shape as inputs.
padding='same')
# Query encoding of shape [batch_size, Tq, filters].
query_seq_encoding = cnn_layer(query_embeddings)
# Value encoding of shape [batch_size, Tv, filters].
value_seq_encoding = cnn_layer(value_embeddings)
# Query-value attention of shape [batch_size, Tq, filters].
query_value_attention_seq = tf.keras.layers.Attention()(
[query_seq_encoding, value_seq_encoding])
# Reduce over the sequence axis to produce encodings of shape
# [batch_size, filters].
query_encoding = tf.keras.layers.GlobalAveragePooling1D()(
query_seq_encoding)
query_value_attention = tf.keras.layers.GlobalAveragePooling1D()(
query_value_attention_seq)
# Concatenate query and document encodings to produce a DNN input layer.
input_layer = tf.keras.layers.Concatenate()(
[query_encoding, query_value_attention])
output = Dense(units=256, activation='relu')(input_layer)
output = Dense(units=128, activation='relu')(output)
output = Dense(units=64, kernel_regularizer=regularizers.l1_l2(l1=0.01, l2=0.01), activation='relu')(output)
output = layers.Dropout(0.4)(output)
Y = Dense(output_dim, activation="softmax",name='final_layer')(output)
model = Model([query_input], Y)
adam=optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(optimizer=adam,
loss='sparse_categorical_crossentropy',
metrics=['acc'])
model.summary()データは他の記事同様、IMDBのレビューを前処理をした後を使っている。
callbacks = [
EarlyStopping(patience=5)
]
seed_everything(42)
# Train the model.
history=model.fit(x=X_train,
y=train_label,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2,
callbacks=callbacks,
shuffle=True)

正答率約83%,F1値0.824であった。
学習的にはうまくいっていそうではあるが、これは、attentionをうまく活用できているのであろうか、、、。
LSTM+self-attention
また、LSTMverも作成してみた。

input_dim = num_words+1 # 入力データの次元数
emb_dim = 300
output_dim = 2 # 出力データの次元数:クラス分
num_hidden_units = 100 # 隠れ層のユニット数
batch_size = 128 # ミニバッチサイズ
epochs = 100 # 学習エポック数# Variable-length int sequences.
query_input = Input(shape=(None,), name='input_q')
# value_input = Input(shape=(None,), name='input_v')##########selfじゃないとき用
# Embedding lookup.
token_embedding = tf.keras.layers.Embedding(input_dim=input_dim, output_dim=emb_dim,
trainable=True, # 埋め込み行列を固定(学習時に更新)
mask_zero=True) # 0をパディング用に特別扱いする)
# Query embeddings of shape [batch_size, Tq, dimension].
query_embeddings = token_embedding(query_input)
# Value embeddings of shape [batch_size, Tv, dimension].
# value_embeddings = token_embedding(value_input)##########selfじゃないとき用
value_embeddings = token_embedding(query_input)
lstm_layer = LSTM(
num_hidden_units,
return_sequences=False,name="lstm")
# Query encoding of shape [batch_size, Tq, filters].
query_seq_encoding = lstm_layer(query_embeddings)
# Value encoding of shape [batch_size, Tv, filters].
value_seq_encoding = lstm_layer(value_embeddings)
# Query-value attention of shape [batch_size, Tq, filters].
query_value_attention = tf.keras.layers.Attention()(
[query_seq_encoding, value_seq_encoding])
# Concatenate query and document encodings to produce a DNN input layer.
input_layer = layers.Concatenate()(
[query_seq_encoding, query_value_attention])
output = Dense(units=256, activation='relu')(input_layer)
output = Dense(units=128, activation='relu')(output)
output = Dense(units=64, kernel_regularizer=regularizers.l1_l2(l1=0.01, l2=0.01), activation='relu')(output)
output = layers.Dropout(0.4)(output)
Y = Dense(output_dim, activation="softmax",name='final_layer')(output)
model = Model([query_input], Y)
adam=optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(optimizer=adam,
loss='sparse_categorical_crossentropy',
metrics=['acc'])
model.summary()callbacks = [
EarlyStopping(patience=5)
]
seed_everything(42)
# Train the model.
history=model.fit(x=X_train,
y=train_label,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2,
callbacks=callbacks,
shuffle=True)


正答率約79%,F1値0.781であった。
学習的にはうまくいっていそう…なのかはわからない。全結合層をいじれば上手くいきそうだが、これも、attentionをうまく活用できているのであろうか、、、。
SeqSelfAttention+BidirectionalLSTM
を参考にモデルを作製してみた。このライブラリは
pip install keras_self_attentionで入れることができる。

input_dim = num_words+1 # 入力データの次元数:実数値1個なので1を指定
emb_dim = 300
output_dim = 2 # 出力データの次元数:クラス分
num_hidden_units = 100 # 隠れ層のユニット数
batch_size = 128 # ミニバッチサイズ
epochs = 100 # 学習エポック数def lstm_att():
model = Sequential()
model.add(Embedding(
input_dim=input_dim, # 入力として取り得るカテゴリ数(パディングの0を含む)# vocabulary_size
output_dim=emb_dim, # 出力ユニット数(本来の特徴量の次元数)
# weights=[embedding_matrix], # 埋め込み行列を指定
# trainable=True, # 埋め込み行列を固定(学習時に更新)
mask_zero=True)) # 0をパディング用に特別扱いする
model.add(layers.Bidirectional(layers.LSTM(units=emb_dim,return_sequences=True)))
model.add(SeqSelfAttention(attention_activation='sigmoid'))
model.add(GlobalMaxPooling1D())
model.add(Dense(100, kernel_regularizer=regularizers.l1_l2(l1=0.01, l2=0.01), activation="relu"))
model.add(layers.Dropout(0.25))
model.add(Dense(output_dim, activation="softmax"))
adam=optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(optimizer=adam,
loss='sparse_categorical_crossentropy',
metrics=['acc'])
model.summary()
return model# # Preparing callbacks.
model_=lstm_att()
callbacks = [
EarlyStopping(patience=5)
]
seed_everything(42)
# Train the model.
history=model_.fit(x=X_train,
y=train_label,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2,
callbacks=callbacks,
shuffle=True)自分のPCでは学習に時間がかかりすぎ、様々な層を試すことができなかったが一応学習はできた。正答率は約70%程ではあったが改善の余地は残っている。
まとめ
終わりに+次回
今回はざっくりとattentionについて学んでみました。まだ曖昧な個所もありますが何周かしてどんどん知識を深めていきたいと思います。
次回はtransformerに関して学びます。
もし、この記事を読んで参考になった・他の記事も読んでみたいと思った方、twitterのフォローボタンを押していただけるとモチベーション向上につながるので、よろしくお願いいたします。
コメント