
「自然言語処理ってなに?」「何から始めればいい?」といったお悩みを解決できるかもしれない記事になっています。 自然言語処理に対して無知すぎた自分が、最新のモデルBERT等を学ぶ前に、まず基本的な手法の一種であるトピックモデルを学び、使えるようになりたいと思い、まとめたことを解説します。
自然言語処理を自分が学んだ流れ(未来も含む)
- テキストの前処理
- トピックモデル
- word2vecなどの単語分散系
- RNNやLSTM、CNNなどのNN系
- transformer関連
- bert関連(未遂)
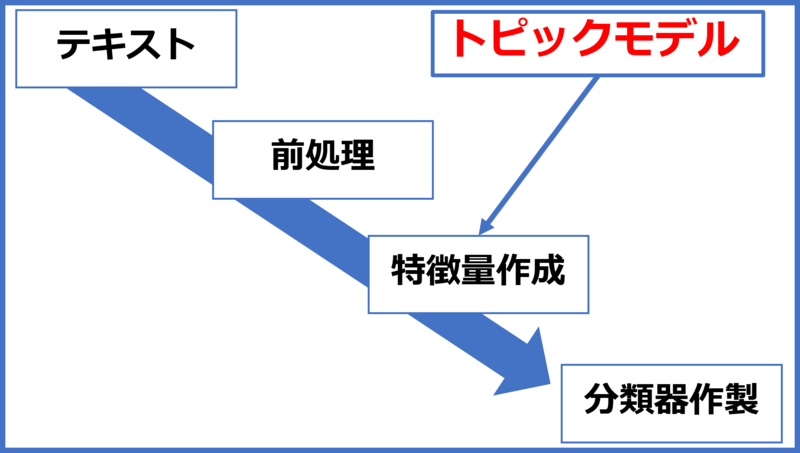
トピックモデルを用いたテキスト分類の流れ
今回はトピックモデルに関してを解説する。
事前に必要な知識
- pythonコードが読めるくらいの知識
- 最低限の数学の知識?
必要なライブラリ
- sklearn
- numpy
- pandas
- BeautifulSoup
- gensim
- nltk
- re
自然言語処理関連を学ぼうとした際の悩みが起こる原因・理由
自然言語処理=言語をコンピュータで解析すること
自然言語処理でできることは、
- テキストデータの解析・分類
- 翻訳
- 対話
- 感情分析
- 検索エンジン
などがある。
人間には簡単に読めている文章でも、コンピュータにとっては文字の意味や文脈を捉えることは困難なことである。といったことを様々な記事で読んだり、思ったりしたことはないでしょうか? だからこそ、研究されている分野であり、天才たちが日々頭を悩ませている分野の1つであるのでしょうか。
そのため、「自然言語処理=難しい」と思い、やめようと思ったことがある人も多いのではないでしょうか?やってみたいと思う気持ちより、難しい印象が勝ってしまう。自分自身も毛嫌いしていたため、なかなか手を出せずにいました…。 そのため、自分が学んだ内容をまとめてみます。
※今回は英文テキストの分類について最後までやっていきたいと思います。
※日本語テキストに関しては後日前処理のみまとめようと思います。
分類までの流れ
前処理→トピックモデル→分類

前処理
自然言語処理では前処理は必須である。
ただ単に羅列した文章をコンピュータが読み取ることはほぼ不可能である。加えて、ノイズや大文字小文字で別の文字判定されてしまうことも・・・。
そのため、前処理・特徴量作製することでコンピュータが読み取れる形にし、学習をおこなう。
クリーニング処理
JavaScriptコード・HTMLタグやurl、さらに文章の開始を示す記号等のノイズを除去する。ノイズは文章を分析する上では不必要である。Pythonでは、Beautiful Soupやreなどが用いられることが多い。
from bs4 import BeautifulSoup # importする
BeautifulSoup(てきすと, "html.parser").get_text()# HTML→クリーニングされた文章単語単位に分割する
英文であれば、単純にスプリットするだけで十分である。
日本語の場合は、単語の区切りが明らかにはなっていないため、形態素解析を用いて分割する。MeCabなどが有名どころである。
"I am a student".split()#"I","am","a","student"
単語の正規化
同じ意味の単語を統一表現にする。つまり、異なる書き方の同じ意味の単語を同じ単語として処理ができるようにすること(Pen,penやイヌ,イヌなど)。
- 文字種の統一(ステミング)
- 辞書を用いた単語の統一
- 省略語、送り仮名違いの処理
などたくさんの工程がある。
ストップワードの除去
自然言語処理する際に一般的で役に立たない等の理由で分析に不必要な単語を除去する工程である。
- 辞書による方式
- 出現頻度による方式
→テキストデータセット内の単語頻度をカウントし、高頻度や低頻度の単語を除去
※高頻度の単語=それらの単語がデータセット中で占める割合が高いため、各文章の違いは見られない
一括で行うコード
import re
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
#nltk.download('wordnet')
#nltk.download('omw-1.4')
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
<span style="color: #ff0000"></span>
import nltk
from nltk.corpus import stopwords
#nltk.download('stopwords')
def clean_text(x):
#ノイズ除去
soup = BeautifulSoup(x, 'html.parser')
text= soup.get_text()
#アルファベット以外をスペースに置き換え
text_ = re.sub(r'[^a-zA-Z]', ' ', text)
#単語長が短いものものは削除(中身による)+その後の処理のために分割
text_ = [word for word in text_.split()]# if len(word) > 1]
#形態素=>動詞
text_ = [lemmatizer.lemmatize(word.lower(), pos="v") for word in text_]
#ステミング
text_ = [stemmer.stem(word) for word in text_]
#stopword除去
A = [word for word in text_ if word not in stopwords.words('english')]
#単語同士をスペースでつなぎ, 文章に戻す
#その後の処理で戻す必要ない場合はコメントアウト
clean_text = ' '.join(A)
return clean_text
clean_text(てきすと)※やる作業・文章によってどの前処理を用いるかはその都度考える。
続きは次の記事で

もし、この記事を読んで参考になった・他の記事も読んでみたいと思った方、twitterのフォローボタンを押していただけるとモチベーション向上につながるので、よろしくお願いいたします。
ChatGPTについて
大規模言語モデル等の台頭により、トピックモデルはなかなか学ばなくなってしまった気もしますので、最近学んだChatGPTでどういう文章を送ればよい答えが返ってくるかということをまとめてみました。


コメント